Optimization of Reinforced Concrete Production and Shipment: A Conveyor-Based Manufacturing and Curing Model#
![]()
![]()


![]()

Introduction#
This optimization model addresses the daily production planning of a precast concrete plant, focused on efficiently fulfilling a complex order of varied concrete products. The plant operates on a conveyor line equipped with 48 moulding pallets, each with fixed dimensions, and relies on controlled curing processes to achieve the necessary concrete strength. A primary challenge is determining the optimal mix of products on each pallet to maximize space utilization, meet strength requirements, and minimize production costs, all while adhering to time-sensitive demand.
Concrete curing time is temperature-dependent, and the plant utilizes a steam chamber to accelerate this process. However, the chamber has constraints on temperature increase rates and cooling requirements, adding complexity to planning. Additionally, the model must manage labor resources effectively to minimize overtime costs, balancing the need for production efficiency against labor expenses.
This model’s objectives are to minimize total production costs, including labor and energy costs associated with curing, while meeting demand and maximizing pallet utilization. By capturing the intricate interactions between curing processes, product placement, and cost factors, this model provides a comprehensive solution for daily production planning, allowing the plant to meet order requirements with optimized resource use and minimal delays.
Tags: Conveyor-Based Manufacturing, Concrete Production, MIP, ampl, Gilmore-Gomory, cbc, cutting-stock, decomposition, industry
Notebook author: Mikhail Riabtsev <mail@solverytic.com>
Problem statement#

A precast concrete plant has received an order to produce a variety of concrete products, requiring a well-optimized daily production plan to balance efficiency, demand, and costs. The plant operates a conveyor line equipped with 48 moulding pallets, each measuring 12,000 x 3,800 mm. The challenge is to determine the optimal number and types of products to place on each pallet, ensuring maximum utilization of available space while minimizing production costs.
Concrete Curing Process#
A critical aspect of production is the concrete curing time, which depends on temperature. The strength development of the concrete is modeled as follows:
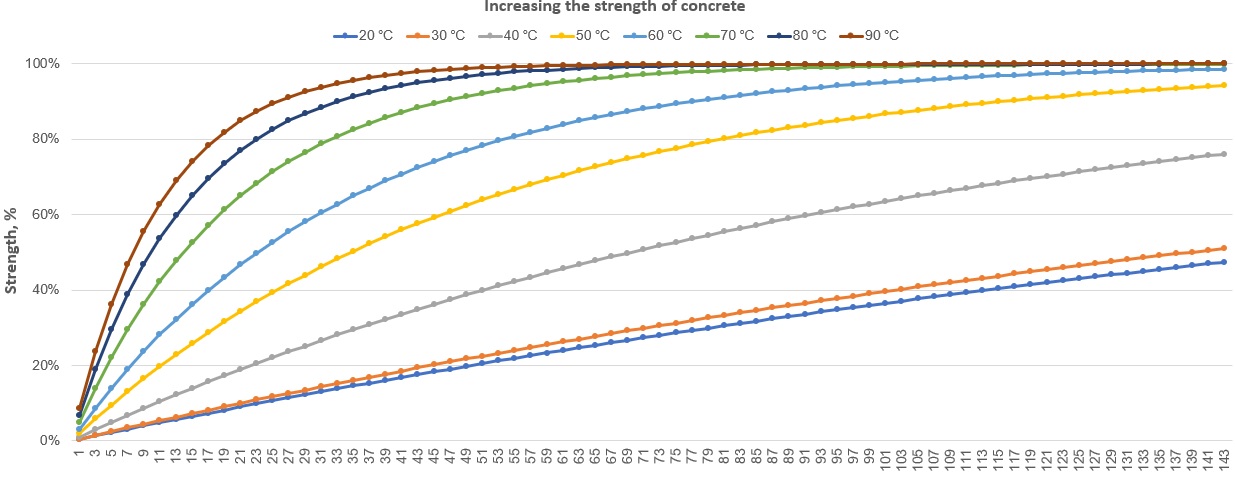
Relative Strength at Initial Temperature \(T_1\) :
\( S_r(t_1) = 1 - exp(-α_1 * (t_1 - t_d)) \)
Where:
\(S_r(t_1) \) : Fraction of the ultimate strength gained after time \(t_1\) at temperature \(T_1\).
\(α_1\) : Rate constant at \(T_1\).
\(t_d\) : Delay time before strength development starts (0 by default).
When the temperature changes to \(T_2\), calculate the equivalent time \(t_e\) at \(T_2\) that corresponds to the relative strength already gained at \(t_1\) :
\(S_r(t_1) = 1 - exp(-α_2 * t_e)\)
Solving for \(t_e\) :
\(t_e = -(1 / α_2) * ln(1 - S_r(t_1))\)
Where:
\(α_2\) - is the rate constant at the new temperature \(T_2\).
\(t_e\) - is the equivalent time at temperature \(T_2\).
After the temperature changes, the relative strength continues to grow based on the new temperature \(T_2\). After spending an additional time \(t_2\) at \(T_2\), the total relative strength is:
\(S_rtotal = 1 - exp(-α_2 * (t_e + t_2))\)
Where:
\(t_2\) - is the additional time spent at temperature \(T_2\).
\(S_rtotal\) - is the total relative strength after both phases (initial time \(t_1\) at \(T_1\) and additional time \(t_2\) at \(T_2\)).
Steam Chamber Process#
To accelerate the curing of concrete, the plant uses a steam chamber with a capacity of 25 pallets. The heating costs depend on the target temperature and are:
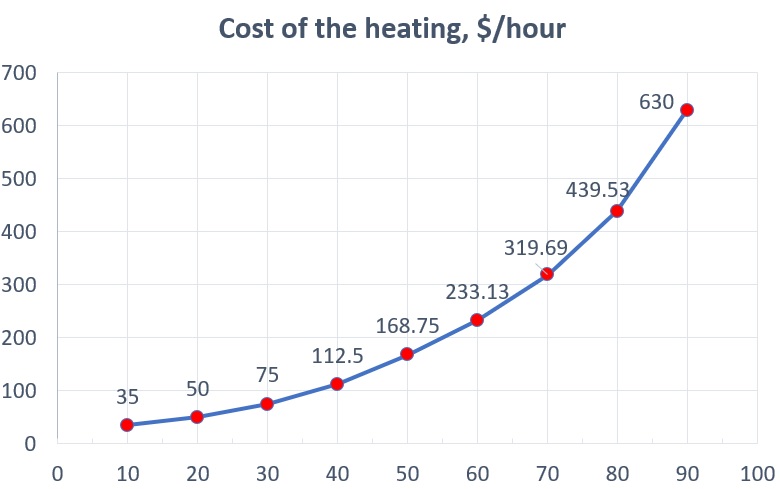
The maximum heating rate of the chamber is limited by the temperature at which there is no deformation of the internal structure of the concrete and is 20°C per hour, and the maximum temperature in the chamber is 90°C. The operating time (heating) of the steam chamber coincides with the operating time of the entire plant. After the end of the operating time, the steam chamber is de-energized and the cooling process begins in it. The chamber gradually cools down at a rate of 10% per hour.
The steam chamber operating parameters (calculated using the data approximation (see *Appendix) and the constructed model of heating and cooling of the steam chamber) are crucial for planning, since its temperature and duration affect production and costs:
Conveyor step, minutes |
Working hours |
Max temperature |
Cycle, days |
Pallets per day |
Pallet per week |
Costs of heating per 1 week |
Cost of employee per 1 week |
Total cost |
|---|---|---|---|---|---|---|---|---|
60 |
9.0 |
71 |
2.5 |
10 |
50 |
11646 |
5000 |
16646 |
60 |
10.0 |
70 |
2.3 |
11 |
55 |
12993 |
6000 |
18993 |
60 |
11.0 |
69 |
2.1 |
12 |
60 |
15336 |
7000 |
22336 |
55 |
9.2 |
73 |
2.3 |
11 |
55 |
14142 |
5500 |
19642 |
55 |
10.1 |
71 |
2.1 |
12 |
60 |
16099 |
6500 |
22599 |
55 |
11.0 |
71 |
1.9 |
13 |
65 |
19165 |
7500 |
26665 |
50 |
9.2 |
74 |
2.1 |
12 |
60 |
17280 |
6000 |
23280 |
50 |
10.0 |
76 |
1.9 |
13 |
65 |
21754 |
7000 |
28754 |
50 |
10.8 |
76 |
1.8 |
14 |
70 |
23428 |
8000 |
31428 |
45 |
9.0 |
80 |
1.9 |
13 |
65 |
23631 |
6500 |
30131 |
45 |
9.8 |
81 |
1.8 |
14 |
70 |
25018 |
7500 |
32518 |
45 |
10.5 |
82 |
1.7 |
15 |
75 |
27663 |
8500 |
36163 |
40 |
8.7 |
90 |
1.8 |
14 |
70 |
31049 |
7000 |
38049 |
40 |
9.3 |
90 |
1.7 |
15 |
75 |
33267 |
8000 |
41267 |
40 |
10.0 |
90 |
1.6 |
16 |
80 |
35485 |
9000 |
44485 |
The above data gives an idea of how the conveyor step time, operating time and temperature adjustment affect the overall cycle time, pallet output and weekly costs. This relationship between cure time, temperature and labor costs influences both planning and resource allocation strategies.
Pallet Dismantling and Product Shipment#
Due to the labor-intensive nature of placing products on a pallet and also to ensure uniform movement of the conveyor, a limitation is imposed on the maximum number of products placed on 1 pallet (no more than 6). Pallets can only be dismantled, and products removed, once the concrete has reached at least 70% of its required strength. After stripping, products can either be stored in a warehouse or shipped directly to construction sites.
Labor and Operational Costs#
Labor costs for producing one pallet are $100. If staff work overtime (beyond 9 hours, including a 1-hour break), labor costs double.
Objective#
The plant’s primary goal is to develop the most cost-effective production plan that meets daily demand, optimizes production schedules, and ensures efficient use of resources and shipping logistics. The plan must consider:
Concrete curing times and strength requirements
Pallet utilization and steam chamber capacity
Shipping constraints and timely product readiness
Minimization of production and operational costs
1. Download Necessary Extensions and Libraries#
Let’s start by downloading the necessary extensions and libraries
# Install dependencies
%pip install -q amplpy pandas numpy seaborn matplotlib jinja2
import pandas as pd # Loading panda to work with pandas.DataFrame objects (https://pandas.pydata.org/)
import numpy as np # Loading numpy to perform multidimensional calculations numpy.matrix (https://numpy.org/)
import math
# Google Colab & Kaggle integration
from amplpy import AMPL, ampl_notebook
ampl = ampl_notebook(
modules=["cbc", "highs", "gurobi"], # modules to install
license_uuid="default", # license to use
) # instantiate AMPL object and register magics
2. Pattern-generation model#
2.1. AMPL Model Formulation#
%%writefile pattern_generation_model.mod
reset;
#############################################
problem Pattern_Opt; ### Master Problem for Molding Optimization
#############################################
### SETS ###
set ITEMS ordered ; # Different products that need molding from the sheets (e.g., parts, components)
param nPAT >= 0, integer; # Total number of patterns to be considered
set PATTERNS = 1..nPAT; # Represents different configurations of patterns used for molding
### PARAMETERS ###
param nDemandWeek >= 0 ; # Number of scheduling periods (weeks)
param items{ITEMS, PATTERNS} >= 0; # Number of items of each product within each pattern
param demand {ITEMS, 1..nDemandWeek} >= 0;# Weekly demand for each item i in ITEMS over the weeks (1 to nDemandWeek)
param sumDemand{i in ITEMS, t in 1..nDemandWeek} = sum {tt in 1..t} demand[i,tt] ; # Cumulative demand up to week t
param binItemLimit integer > 0; # Max number of items per bin to avoid overloading
### VARIABLES ###
var Mold {PATTERNS, 1..nDemandWeek} integer >= 0; # Number of patterns molded for each week
### OBJECTIVE FUNCTION ###
minimize TotalPallets: sum {p in PATTERNS, t in 1..nDemandWeek} Mold[p,t]; # Minimize total patterns molded over all weeks
### CONSTRAINTS ###
s.t. OrderLimits {i in ITEMS, t in 1..nDemandWeek}: # Ensure molding meets demand for each item up to week t
sum {p in PATTERNS, tt in 1..t} Mold[p,tt] * items[i,p] >= sumDemand[i,t] ;
#############################################
problem Pattern_Gen; ### Subproblem for Pattern Generation
#############################################
### SETS ###
set ATR = { 'width', 'height','quantity'};# Attributes for each product (width, height, quantity)
set DIFF = {'quantity'}; # Attributes that vary by item (quantity in this case)
### PARAMETERS ###
param prod {ITEMS, ATR} >= 0 ; # Product dimensions and quantity for each item
param price {ITEMS} default 0; # Price or value of each item for objective function
## Bins
param binDim {ATR diff DIFF} >= 0 ; # Dimensions of each bin (width, height); excludes quantity
### VARIABLES ###
var Use {ITEMS} integer >= 0 ; # Number of each item used in the pattern
### OBJECTIVE FUNCTION ###
minimize Reduced_Cost: 1- sum {i in ITEMS} price[i] * Use[i]; # Minimize total value of items used in the pattern
### CONSTRAINTS ###
s.t. Width_Limit: # Ensure items fit within bin width
sum {i in ITEMS} Use[i] * prod [i,'width'] <= binDim['width'] ;
s.t. Items_limit: # Ensure number of items does not exceed binItemLimit
sum {i in ITEMS} Use[i] <= binItemLimit ;
Overwriting pattern_generation_model.mod
2.2. Load data#
ampl.read("pattern_generation_model.mod") # Load the AMPL model from the file
df = pd.read_csv("concrete_demand.csv") # Load the CSV data into a pandas DataFrame
ampl.set["ITEMS"] = set(df["Name"]) # Create the set PROD from the 'Name' column
ampl.param["binDim"] = {"width": 12000, "height": 3800}
ampl.param["nDemandWeek"] = 9
ampl.param["binItemLimit"] = 10
# Maximum height allowed
max_height = ampl.param["binDim"]["height"]
# Since we are using the 1D Cutting_Stock_Problem algorithm for this problem, for greater efficiency we will orient all the products on the pallets in such a way as to try to fill the pallet as much as possible with one row of products.
# For this we will rotate items if necessary:
def rotate_item(row):
width, height = row["Width"], row["Height"]
# Check if rotating will lead to better width and valid height
if height <= max_height and height < width:
return pd.Series([height, width]) # Swap width and height
else:
if height <= max_height and height >= width:
return pd.Series([width, height]) # Keep original
return pd.Series([height, width])
df[["New_Width", "New_Height"]] = df.apply(rotate_item, axis=1)
prodAtr_dict = {} # Initialize the dictionary for prodAtr
for index, row in df.iterrows(): # Populate the dictionary
prod_type = row["Name"]
prodAtr_dict[(prod_type, "width")] = row["New_Width"]
prodAtr_dict[(prod_type, "height")] = row["New_Height"]
prodAtr_dict[(prod_type, "quantity")] = row["Quantity"]
ampl.param["prod"] = prodAtr_dict # Set the parameter in AMPL
# print(prodAtr_dict )
2.3. Generating data for weekly Items demand#
import random
n_weeks = int(ampl.param["nDemandWeek"].value()) # Number of weeks to generate data for
daily_data = {} # Dictionary to store the generated weekly quantities for each item
# Loop through each item and generate random weekly quantities
for item in set(k[0] for k in prodAtr_dict.keys() if "quantity" in k):
limit = prodAtr_dict[(item, "quantity")] # Max quantity for this item
total_generated = 0 # Track the total generated quantity for the item
weekly_quantities = []
for week in range(n_weeks):
remaining_weeks = n_weeks - week # Weeks left to generate data
remaining_limit = limit - total_generated # Remaining quantity to distribute
if remaining_limit <= 0:
weekly_quantities.append(0) # No more quantity to allocate
continue
if remaining_weeks == 1:
weekly_quantity = remaining_limit # Ensure the last week's quantity makes the total sum equal to 'limit'
else:
# Generate a random quantity, ensuring that there's enough left for future weeks
max_quantity = min(remaining_limit, random.randint(0, 10))
weekly_quantity = random.randint(0, max_quantity)
# Add the generated quantity and update the total
total_generated += weekly_quantity
weekly_quantities.append(weekly_quantity)
daily_data[item] = weekly_quantities # Store the generated data
# Assign the data to the AMPL param 'demand'
for item, values in daily_data.items():
for t in range(1, n_weeks + 1): # t is inclusive from 1 to n_weeks
ampl.getParameter("demand")[item, t] = values[t - 1]
demand_data = {} # Create a dictionary to store the demand data
# Loop through each item in the AMPL parameter 'demand'
for item in set(k[0] for k in prodAtr_dict.keys() if "quantity" in k):
demand_data[item] = [] # Initialize the list for the current item's demand
# Loop through each time period (from 1 to n_weeks)
for t in range(1, n_weeks + 1):
demand_value = ampl.param["demand"][
item, t
] # Retrieve the demand value for the current item and time period
demand_data[item].append(
demand_value
) # Append the demand value to the item's list in the dictionary
2.4. Solve problem (Gilmore-Gomory method)#
# Set the solver type for use in solving the problems
solver = "cbc" # Define the solver as CBC for all problem-solving steps
# Define two subproblems: the main optimization problem (Pattern_Opt) and an auxiliary pattern generation problem (Pattern_Gen)
for problem in ["Pattern_Opt", "Pattern_Gen"]:
ampl.eval(
f"""
problem {problem};
option relax_integrality {0 if problem == 'Pattern_Gen' else 1};
option presolve {1 if problem == 'Pattern_Gen' else 0};
option solver {solver}; # Use the defined solver variable
option cbc_options 'outlev=1 lim:time=20'; # Set main solver options for output level and time limit
"""
)
# Initialize pattern count and define the items set
ampl.param["nPAT"] = 0
ITEMS = set(df["Name"])
# Function definitions for generating initial patterns
def generate_initial_patterns(model, item):
model.eval(
f"""
let nPAT := nPAT + 1; # Increment pattern count for each width
let items['{item}', nPAT] := # Set the count of rolls that fit for each width in the initial pattern
min(floor(binDim['width'] / prod['{item}','width']), binItemLimit);
let {{i2 in ITEMS: i2 != '{item}'}} items[i2, nPAT] := 0; # Initialize other widths in this pattern to zero
"""
)
# Function adding new patterns remain unchanged
def add_new_pattern(model):
model.eval(
"""
let nPAT := nPAT + 1; # Add a new pattern if reduced cost is sufficiently negative
let {i in ITEMS} items[i, nPAT] := Use[i]; # Update the pattern with item counts for each width
"""
)
# Generate initial patterns for each item
[generate_initial_patterns(ampl, i) for i in ITEMS]
# Initialize iteration parameters
iterations = 0
max_iterations = 10000
# Iteratively solve the main optimization problem and generate new patterns as needed
while iterations < max_iterations:
iterations += 1 # Increment iteration counter
# Solve the main Molding optimization problem using the specified solver
ampl.solve(problem="Pattern_Opt", solver=solver, verbose=False)
# Retrieve dual prices from the solution of Pattern_Opt
ampl.eval(
"let {i in ITEMS, t in 1..nDemandWeek} price[i] := OrderLimits[i,t].dual;"
) # Get dual prices (shadow prices) for each width from Pattern_Opt solution
# Solve the pattern generation problem using the same solver
ampl.solve(
problem="Pattern_Gen", solver=solver, verbose=False
) # Solve pattern generation with current dual prices
assert ampl.solve_result == "solved", ampl.solve_result
# Check for beneficial patterns and add if necessary
if (
ampl.obj["Reduced_Cost"].value() < -0.00001
): # Check if new pattern is beneficial (i.e., if reduced cost is negative)
add_new_pattern(ampl) # Add new pattern based on current usage
else:
break # Exit loop if no beneficial pattern is found
# Display results
ampl.display("items") # Final pattern matrix
ampl.display("Mold") # Molding quantities
# Finalize the solution and solve the integral problem
ampl.eval(
"option Pattern_Opt.relax_integrality 0; option Pattern_Opt.presolve 10; option show_stats 1;"
)
ampl.solve(
problem="Pattern_Opt", solver=solver, verbose=False
) # Solve the final integral problem
assert ampl.solve_result in ["solved", "limit"], ampl.solve_result
ampl.display(
"Mold", "TotalPallets"
) # Display the final molding quantities for each pattern
# Convert total pallets produced to an integer value
total_pallets_value = int(ampl.obj["TotalPallets"].value())
items [*,*] (tr)
# $1 = 3HS10_3
# $2 = 3HS48_3
# $3 = 3HS31_6
# $4 = 3HS31_3
# $5 = 3HS60_1
# $6 = 3HS31_7
# $7 = 3HS50_1
# $8 = 3HS10_2
# $9 = 3HS31_5
# $10 = 3HS59_1
# $11 = 3HS18_2
# $12 = 3HS59_2
# $13 = 3HS48_1
# $14 = 3HS17_1
# $15 = 3HS18_4
# $16 = 3HS10_4
# $17 = 3HS50_2
# $18 = 3HS14_2
: $1 $2 $3 $4 $5 $6 $7 $8 $9 $10 $11 $12 $13 $14 $15 $16 $17 $18 :=
1 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0
8 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0
13 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0
14 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 0 0 0
15 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0
16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 0 0
17 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0
18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8
19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
23 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
24 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
26 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
28 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
29 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
30 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0
31 2 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0
32 7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
33 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 0
34 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1
35 0 0 0 0 0 0 0 0 0 0 0 0 0 1 5 0 0 1
36 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 6
37 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0
38 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 1
39 2 0 0 0 0 0 0 0 0 0 0 0 0 6 0 0 0 0
40 2 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 3
41 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 2 0 3
42 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 2 0 0
43 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1
44 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
45 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 2 0
46 1 0 0 0 0 0 0 0 0 0 0 1 0 2 0 0 0 0
47 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
# $8 = 3HS48_2
# $9 = 3HS31_1
# $11 = 3HS31_8
: 3HS31_4 3HS31_2 3HS18_3 3HS33_1 3HS18_1 3HS33_2 3HS14_1 $8 $9 3HS10_1 $11 :=
1 0 0 0 0 0 0 0 0 0 0 0
2 0 0 0 0 0 0 0 0 0 0 0
3 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0 0 0 0
8 0 0 0 0 0 0 0 0 0 0 0
9 0 0 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0 0 0
11 0 0 0 0 0 0 0 0 0 0 0
12 0 0 0 0 0 0 0 0 0 0 0
13 0 0 0 0 0 0 0 0 0 0 0
14 0 0 0 0 0 0 0 0 0 0 0
15 0 0 0 0 0 0 0 0 0 0 0
16 0 0 0 0 0 0 0 0 0 0 0
17 0 0 0 0 0 0 0 0 0 0 0
18 0 0 0 0 0 0 0 0 0 0 0
19 4 0 0 0 0 0 0 0 0 0 0
20 0 4 0 0 0 0 0 0 0 0 0
21 0 0 6 0 0 0 0 0 0 0 0
22 0 0 0 4 0 0 0 0 0 0 0
23 0 0 0 0 6 0 0 0 0 0 0
24 0 0 0 0 0 4 0 0 0 0 0
25 0 0 0 0 0 0 8 0 0 0 0
26 0 0 0 0 0 0 0 2 0 0 0
27 0 0 0 0 0 0 0 0 4 0 0
28 0 0 0 0 0 0 0 0 0 10 0
29 0 0 0 0 0 0 0 0 0 0 4
30 0 0 0 0 0 0 0 0 0 0 0
31 0 0 0 0 0 0 0 0 0 0 0
32 0 0 3 0 0 0 0 0 0 0 0
33 0 0 3 0 0 0 0 0 0 0 0
34 0 0 5 0 0 0 0 0 0 0 0
35 0 0 0 0 0 0 0 0 0 0 0
36 0 0 1 0 0 0 0 0 0 0 0
37 0 0 1 0 0 0 6 0 0 0 0
38 0 0 0 0 0 1 0 0 0 0 0
39 0 0 0 0 0 0 0 0 0 0 0
40 0 0 0 0 0 0 0 0 0 0 0
41 0 0 0 0 0 0 0 0 0 0 0
42 0 0 0 0 0 0 3 0 0 0 0
43 0 0 0 0 0 1 0 0 0 0 0
44 0 0 4 0 0 1 0 0 0 0 0
45 0 0 0 0 0 0 0 0 0 0 0
46 0 0 1 0 0 0 0 0 0 0 0
47 0 0 4 1 0 0 0 0 0 0 0
;
Mold [*,*]
: 1 2 3 4 5 6 7 8 :=
1 0 0 0 0 0 0 0 0
2 2.5 1 3 0 0 0 1.5 0
3 0 0.25 0 0.25 0 0 0 0
4 0.75 0 1.75 0 0 0 0.5 0
5 0.5 0 4 2.5 0 0 0 1.5
6 0.5 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0
8 0.2 0.1 0 0 0 0 0 0
9 0.5 0 0 0 0 0 0 0
10 1 4.5 4.5 0 0 2.5 1 0.5
11 0.833333 0.666667 1 0 0 0 0.166667 0
12 0.666667 0 0 0 0 0 0 0
13 2.5 0 0 1 1 1.5 1.5 0.5
14 0 0 0 0 0 0 0 0
15 0 0 0 0 0 0 0 0
16 0 0 0 0 0 0 0 0
17 0 0 0 0 0 0 0 0
18 0 0 0 0 0 0 0 0
19 0.75 0 2.25 0 0 0 0.25 0.5
20 0.75 1.25 0 0 0.75 0.5 0 0.5
21 0 0 0 0 0 0 0 0
22 0.75 0 2 0 0 0 1.75 0.5
23 1 0 1.66667 0 0 0 0 0
24 0 0 0 0 0 0 0 0
25 0 0 0 0 0 0 0 0
26 3.5 0 0 4.5 0 0 0 0
27 0.5 0 4.25 0 0 0 0.25 1.75
28 0.3 0 0 0 0 0 0 0
29 0.25 0.25 0 0 0 0 0 0
30 0.5 0 2.33333 0 0 2.5 1.5 0
31 1.5 0.5 3.5 0 0 1 0 0
32 0 0 0 0 0 0 0 0
33 0 0 0 0 0 0 0 0
34 0 0.266667 0 0 0 0 0 0
35 0.4 0 1.6 0 0 0.8 1.4 0.4
36 0 0 0 0 0 0 0 0
37 0 0 0 0 0 0 0 0
38 0 0 0 0 0 0 0 0
39 0 0 0 0 0 0 0 0
40 0 0 0 0 0 0 0 0
41 0 0.666667 4.66667 0 0 0 0 0
42 1 0.333333 4 0 0 0 0.333333 0
43 9.66667 0 2.33333 0 0 0 2.66667 0
44 1.25 0.916667 1 0 0 0 2 0
45 0 0 0.666667 0 0 0 0 0
46 0 0 0 0 0 0 0 0
47 0 0 1 0 0 0 0 0
: 9 :=
1 0
2 0
3 0
4 4
5 12.5
6 0
7 0
8 0
9 0
10 10
11 0
12 0
13 0
14 0
15 0
16 0
17 0
18 0
19 3.5
20 4.25
21 0
22 2.75
23 0
24 0
25 0
26 0
27 1.25
28 0
29 0
30 0
31 1.5
32 0
33 0
34 0
35 1.8
36 0
37 0
38 0
39 0
40 0
41 0
42 10.3333
43 10.6667
44 1.5
45 0.5
46 0
47 0
;
Presolve eliminates 0 constraints and 423 variables.
Adjusted problem:
29 variables, all integer
2 constraints, all linear; 58 nonzeros
2 inequality constraints
1 linear objective; 18 nonzeros.
Mold [*,*]
: 1 2 3 4 5 6 7 8 9 :=
1 0 0 0 0 0 0 0 0 0
2 3 1 3 0 0 0 1 0 0
3 1 0 0 0 0 0 0 0 0
4 1 0 0 1 1 0 0 0 4
5 7 0 0 0 0 0 0 2 12
6 1 0 0 0 0 0 0 0 0
7 0 0 0 0 0 0 0 0 0
8 1 0 0 0 0 0 0 0 0
9 1 0 0 0 0 0 0 0 0
10 6 0 7 0 0 0 1 0 10
11 1 1 0 1 0 0 0 0 0
12 0 0 1 0 0 0 3 0 0
13 0 0 4 0 1 1 2 0 0
14 0 0 0 0 0 0 0 0 0
15 0 0 0 0 2 0 0 0 0
16 0 0 0 0 0 0 0 0 0
17 0 0 0 0 0 0 0 0 0
18 0 0 0 0 0 0 1 0 0
19 3 0 0 0 0 0 1 0 4
20 2 0 0 0 1 1 0 0 4
21 0 0 0 0 0 0 0 0 0
22 1 0 2 0 0 0 2 1 2
23 3 0 0 0 0 0 0 0 0
24 0 0 0 3 0 0 0 0 0
25 0 0 0 0 0 0 0 0 0
26 4 0 4 0 0 0 0 0 0
27 1 4 0 0 0 0 0 2 1
28 0 0 1 0 0 0 0 0 0
29 1 0 0 0 0 0 0 0 0
30 0 3 0 0 0 0 0 0 0
31 2 0 1 4 0 0 0 0 1
32 0 0 0 0 0 0 0 0 1
33 1 0 0 0 0 0 0 0 0
34 0 3 0 0 0 0 0 0 0
35 4 0 0 0 0 0 0 0 0
36 0 0 0 0 0 0 0 0 0
37 0 0 0 0 0 0 0 1 0
38 0 0 0 0 0 0 0 0 0
39 0 0 0 0 0 0 0 0 0
40 0 0 5 0 0 0 0 0 0
41 0 0 0 0 0 0 0 0 0
42 14 0 0 0 0 0 0 0 0
43 0 0 0 0 0 0 18 0 0
44 2 0 0 0 0 0 0 0 0
45 5 0 0 0 0 0 0 0 0
46 0 0 3 0 0 0 0 0 0
47 0 0 0 0 0 0 0 0 0
;
TotalPallets = 198
2.5. Retrieve solution in Python#
# Filter 'items' parameter to exclude zero values
Pattern_items_ = {k: v for k, v in ampl.param["items"].to_dict().items() if v != 0}
# Round values in filtered dictionary
Pattern_items = {k: round(v) for k, v in Pattern_items_.items()}
3. Steam chamber problem#
3.1. AMPL Model Formulation#
%%ampl_eval
problem Steam_chamber_problem ;
### Previously declared objects:
# SETS: ITEMS, ATR, PATTERNS
# PARAMETERS: prod, nDemandWeek, demand, items
### SETS ###
set MODE ; # Set MODE represents the different modes of production
set MODE_ATR ; # Set MODE_ATR defines the various attributes of each production mode
### PARAMETERS ###
param mode_atr{MODE, MODE_ATR} >= 0 ; # Attributes for each production mode
param discount := 0.05/52 ; # Discount rate of 5% applied to the costs include cost of storing items in the warehouse
param nWeek >= 0 ; # Total weeks in scheduling period nDemandWeek + the period required to produce the ordered batch with minimum productivity
param n = nWeek - nDemandWeek ; # initial produced period (nWeek - nDemandWeek)
param nDemandWeek_max {i in ITEMS} := # Maximum week where demand > 0 for each item
max {t in 1..nDemandWeek: demand[i,t] > 0} t;
param endPeriod{i in ITEMS} = # Compute the effective number of weeks (nWeek_) required to meet demand, starting after the last demand week
nWeek - nDemandWeek + nDemandWeek_max[i] ;
set LINKS = {i in ITEMS, 1..endPeriod[i]}; #
set LINKS_DEMAND = {i in ITEMS, n+1..endPeriod[i]} ; # Set LINKS captures the items and the extended demand weeks beyond the initial demand horizon
param initial_stock {ITEMS} default 0 >= 0; # Initial stock for each item in the warehouse at the beginning of the planning period
param max_storage {ITEMS} default 10e5 >= 0; # Maximum storage capacity available for each item in the warehouse
### VARIABLES ###
var ModeUsed {MODE, 1..nWeek} binary; # Indicate if mode m is used during week t
var PatternUsed {PATTERNS, 1..nWeek} >= 0, integer; # 1 if the pallet is produced during the nWeek week using the MODE mode
var Storage {LINKS} >= 0; # Ensure that items can be stored if not immediately transported, and it helps manage inventory over time
var Produce {i in ITEMS, t in 1..nWeek} =
sum{p in PATTERNS} PatternUsed[p,t] * items[i,p] ;
### OBJECTIVE FUNCTION ###
# Minimize the total cost, which consists of production costs and discounted storage costs
minimize Total_Cost:
sum {t in 1..nWeek} ( # Production costs include costs of heating and employee costs for each mode
sum{m in MODE} ModeUsed[m,t] * mode_atr[m, 'Total cost']
+ sum{(i,t) in LINKS} Storage[i,t]
- sum{(i,tt) in LINKS_DEMAND} demand[i,tt - n])
* (1 + discount)^(nWeek - t); # Apply discount to all costs
### CONSTRAINTS ###
# 1. Ensure that only one mode is used in each week across all bins
s.t. One_Mode_Per_Week {t in 1..nWeek}:
sum {m in MODE} ModeUsed[m,t] <= 1; # Only one mode can be active in week t
# 2. Weekly pallet capacity
s.t. Pallet_Capacity {t in 1..nWeek}:
sum {p in PATTERNS, i in ITEMS} PatternUsed[p,t] * items[i,p]
<= sum{m in MODE} ModeUsed[m,t] * mode_atr[m, 'Pallet per week'];
# 3. Demand satisfaction with produced pallets
s.t. Pallet_Fulfillment {(i,t) in LINKS_DEMAND}:
sum {p in PATTERNS, tt in 1..t} PatternUsed[p,tt] * items[i,p]
>= sum{tt in n+1..t} demand[i,tt - n];
# 4. The amount of items stored at the end of a given week should equal the initial stock (for week 1) or the sum of the previous week's storage and current production minus transported items
s.t. Inventory_Balance {(i,t) in LINKS}:
Storage[i,t] =
(if t > 1 then Storage[i,t-1] else initial_stock[i])
+ sum {p in PATTERNS} PatternUsed[p,t] * items[i,p]
- sum{(i,w) in LINKS_DEMAND: w = t} demand[i,w-n] ;
# 5. Ensure that the amount of items stored at any week does not exceed the maximum storage capacity for that item
s.t. Storage_Limit {(i,t) in LINKS}:
Storage[i,t] <= max_storage[i];
3.2. Load data#
# Define production mode data with respective attributes
data = [
("60_9.2", 60, 9.0, 71, 2.5, 10, 50, 11646, 5000, 16646),
("60_10", 60, 10.0, 70, 2.3, 11, 55, 12993, 6000, 18993),
("60_11", 60, 11.0, 69, 2.1, 12, 60, 15336, 7000, 22336),
("55_9.2", 55, 9.2, 73, 2.3, 11, 55, 14142, 7000, 19642),
("55_10.1", 55, 10.1, 71, 2.1, 12, 60, 16099, 6500, 22599),
("55_11", 55, 11.0, 71, 1.9, 13, 65, 19165, 7500, 26665),
("50_9.2", 50, 9.2, 74, 2.1, 12, 60, 17280, 6000, 23280),
("50_10", 50, 10.0, 76, 1.9, 13, 65, 21754, 7000, 28754),
("50_10.8", 50, 10.8, 76, 1.8, 14, 70, 23428, 8000, 31428),
("45_9", 45, 9.0, 80, 1.9, 13, 65, 23631, 6500, 30131),
("45_9.8", 45, 9.8, 81, 1.8, 14, 70, 25018, 7500, 32518),
("45_10.5", 45, 10.5, 82, 1.7, 15, 75, 27663, 8500, 36163),
("40_8.7", 40, 8.7, 90, 1.8, 14, 70, 31049, 7000, 38049),
("40_9.3", 40, 9.3, 90, 1.7, 15, 75, 33267, 8000, 41267),
("40_10", 40, 10.0, 90, 1.6, 16, 80, 35485, 9000, 44485),
]
# Column mapping for mode_atr parameter attributes (optional, just for reference)
mode_atr_keys = [
"Conveyor step", # Conveyor step duration for each production mode
"Working hours", # Number of working hours per day in each mode
"Max temperature", # Maximum temperature used in the process in each mode
"Cycle, days", # Number of days in the production cycle for each mode
"Pallets per day", # Number of pallets produced per day in each mode
"Pallet per week", # Number of pallets produced per week in each mode
"Costs of heating", # Heating cost for production in each mode
"Cost of employee", # Employee cost for production in each mode
"Total cost",
]
# Calculate required production weeks, rounding up, and add extra weeks
ampl.param["nWeek"] = (
math.ceil(total_pallets_value / min(row[6] for row in data)) + n_weeks
)
ampl.set["MODE"] = [
row[0] for row in data
] # Define production modes in the AMPL set 'MODE'
ampl.set["MODE_ATR"] = set(
mode_atr_keys
) # Define attribute names in the AMPL set 'MODE_ATR'
# Assign the values from the data list to the AMPL parameter 'mode_atr'
for mode_data in data:
mode = mode_data[0] # Extract the mode name from the first element of each tuple
for i, atr in enumerate(mode_atr_keys):
value = mode_data[
i + 1
] # Retrieve the corresponding attribute value (skip the mode name)
ampl.getParameter("mode_atr")[
mode, atr
] = value # Assign each value to its corresponding mode and attribute in AMPL
3.3. Solve problem#
%%ampl_eval
#reset problem Steam_chamber_problem;
# Defining Output Settings
problem Steam_chamber_problem ;
option show_stats 1; # (1) Show statistical information about the size of the problem. Default 0 (statistics are not displayed)
option display_1col 0; # Data Display Settings
option omit_zero_rows 1; # Hide rows with 0 values. Default (0)
option solver cbc ;
option cbc_options 'outlev=1 lim:time=60';
solve ;
Presolve eliminates 335 constraints and 452 variables.
Substitution eliminates 377 variables.
Adjusted problem:
1127 variables:
195 binary variables
611 integer variables
321 linear variables
538 constraints, all linear; 8009 nonzeros
321 equality constraints
217 inequality constraints
1 linear objective; 516 nonzeros.
cbc 2.10.10: tech:outlev = 1
lim:time = 60
Welcome to the CBC MILP Solver
Version: 2.10.10
Build Date: Sep 5 2023
command line - Cbc_C_Interface -log 1 -solve -quit (default strategy 1)
Continuous objective value is 251798 - 0.02 seconds
Cgl0003I 0 fixed, 155 tightened bounds, 51 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 51 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 51 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 51 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 51 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 39 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 29 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 24 strengthened rows, 0 substitutions
Cgl0003I 0 fixed, 0 tightened bounds, 22 strengthened rows, 0 substitutions
Cgl0004I processed model has 372 rows, 801 columns (646 integer (91 of which binary)) and 7413 elements
Cbc0031I 57 added rows had average density of 149.07018
Cbc0013I At root node, 57 cuts changed objective from 266559.2 to 271319.43 in 10 passes
Cbc0014I Cut generator 0 (Probing) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.052 seconds - new frequency is -100
Cbc0014I Cut generator 1 (Gomory) - 243 row cuts average 445.6 elements, 0 column cuts (0 active) in 0.099 seconds - new frequency is 1
Cbc0014I Cut generator 2 (Knapsack) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.007 seconds - new frequency is -100
Cbc0014I Cut generator 3 (Clique) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.000 seconds - new frequency is -100
Cbc0014I Cut generator 4 (MixedIntegerRounding2) - 77 row cuts average 13.4 elements, 0 column cuts (0 active) in 0.096 seconds - new frequency is 1
Cbc0014I Cut generator 5 (FlowCover) - 0 row cuts average 0.0 elements, 0 column cuts (0 active) in 0.044 seconds - new frequency is -100
Cbc0014I Cut generator 6 (TwoMirCuts) - 160 row cuts average 91.0 elements, 0 column cuts (0 active) in 0.030 seconds - new frequency is 1
Cbc0014I Cut generator 7 (ZeroHalf) - 10 row cuts average 71.8 elements, 0 column cuts (0 active) in 0.017 seconds - new frequency is -100
Cbc0010I After 0 nodes, 1 on tree, 1e+50 best solution, best possible 271319.43 (1.14 seconds)
Cbc0010I After 1000 nodes, 346 on tree, 1e+50 best solution, best possible 271319.43 (5.98 seconds)
Cbc0010I After 2000 nodes, 557 on tree, 1e+50 best solution, best possible 271319.43 (8.36 seconds)
Cbc0010I After 3000 nodes, 561 on tree, 1e+50 best solution, best possible 271319.43 (11.03 seconds)
Cbc0010I After 4000 nodes, 546 on tree, 1e+50 best solution, best possible 271319.43 (13.64 seconds)
Cbc0010I After 5000 nodes, 555 on tree, 1e+50 best solution, best possible 271319.43 (15.53 seconds)
Cbc0010I After 6000 nodes, 809 on tree, 1e+50 best solution, best possible 271319.43 (17.60 seconds)
Cbc0010I After 7000 nodes, 797 on tree, 1e+50 best solution, best possible 271319.43 (19.49 seconds)
Cbc0010I After 8000 nodes, 780 on tree, 1e+50 best solution, best possible 271319.43 (21.53 seconds)
Cbc0010I After 9000 nodes, 780 on tree, 1e+50 best solution, best possible 271319.43 (23.86 seconds)
Cbc0010I After 10000 nodes, 863 on tree, 1e+50 best solution, best possible 271319.43 (27.69 seconds)
Cbc0010I After 11000 nodes, 921 on tree, 1e+50 best solution, best possible 271319.43 (30.40 seconds)
Cbc0010I After 12000 nodes, 1434 on tree, 1e+50 best solution, best possible 271319.43 (33.84 seconds)
Cbc0010I After 13000 nodes, 1943 on tree, 1e+50 best solution, best possible 271319.43 (37.16 seconds)
Cbc0010I After 14000 nodes, 2063 on tree, 1e+50 best solution, best possible 271319.43 (40.00 seconds)
Cbc0010I After 15000 nodes, 2081 on tree, 1e+50 best solution, best possible 271319.43 (41.89 seconds)
Cbc0010I After 16000 nodes, 2094 on tree, 1e+50 best solution, best possible 271319.43 (43.79 seconds)
Cbc0010I After 17000 nodes, 2108 on tree, 1e+50 best solution, best possible 271319.43 (45.81 seconds)
Cbc0010I After 18000 nodes, 2328 on tree, 1e+50 best solution, best possible 271319.43 (47.83 seconds)
Cbc0010I After 19000 nodes, 2341 on tree, 1e+50 best solution, best possible 271319.43 (49.20 seconds)
Cbc0010I After 20000 nodes, 2322 on tree, 1e+50 best solution, best possible 271319.43 (51.24 seconds)
Cbc0010I After 21000 nodes, 2324 on tree, 1e+50 best solution, best possible 271319.43 (53.43 seconds)
Cbc0010I After 22000 nodes, 2539 on tree, 1e+50 best solution, best possible 271319.43 (55.76 seconds)
Cbc0010I After 23000 nodes, 2530 on tree, 1e+50 best solution, best possible 271319.43 (58.01 seconds)
Cbc0004I Integer solution of 285440.19 found after 241019 iterations and 23079 nodes (58.21 seconds)
Cbc0038I Full problem 372 rows 801 columns, reduced to 162 rows 177 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 157 rows 174 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 173 rows 187 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 154 rows 170 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 158 rows 176 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 167 rows 187 columns
Cbc0038I Full problem 372 rows 801 columns, reduced to 166 rows 180 columns
Cbc0020I Exiting on maximum time
Cbc0005I Partial search - best objective 285440.19 (best possible 271319.43), took 247958 iterations and 23600 nodes (59.85 seconds)
Cbc0032I Strong branching done 37130 times (257696 iterations), fathomed 2779 nodes and fixed 4670 variables
Cbc0035I Maximum depth 376, 164 variables fixed on reduced cost
Cuts at root node changed objective from 266559 to 271319
Probing was tried 10 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.052 seconds)
Gomory was tried 5158 times and created 5247 cuts of which 0 were active after adding rounds of cuts (1.836 seconds)
Knapsack was tried 10 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.007 seconds)
Clique was tried 10 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.000 seconds)
MixedIntegerRounding2 was tried 5158 times and created 6638 cuts of which 0 were active after adding rounds of cuts (3.343 seconds)
FlowCover was tried 10 times and created 0 cuts of which 0 were active after adding rounds of cuts (0.044 seconds)
TwoMirCuts was tried 5158 times and created 9559 cuts of which 0 were active after adding rounds of cuts (2.118 seconds)
ZeroHalf was tried 10 times and created 10 cuts of which 0 were active after adding rounds of cuts (0.017 seconds)
Result - Stopped on time limit
Objective value: 285440.19200517
Lower bound: 271319.429
Gap: 0.05
Enumerated nodes: 23600
Total iterations: 247958
Time (CPU seconds): 59.87
Time (Wallclock seconds): 65.64
Total time (CPU seconds): 59.87 (Wallclock seconds): 65.64
cbc 2.10.10: hit a limit, feasible solution returned; objective 285440.192
247958 simplex iterations
247958 barrier iterations
23600 branching nodes
absmipgap=14120.8, relmipgap=0.0494701
assert ampl.solve_result in ["solved", "limit"], ampl.solve_result
3.4. Retrieve solution in Python#
# Filter non-zero values from the PatternUsed variable and round them
Pattern_used_ = {k: v for k, v in ampl.var["PatternUsed"].to_dict().items() if v != 0}
Pattern_used = {k: round(v) for k, v in Pattern_used_.items()}
# Filter non-zero values from the Storage variable and round them
Storage_ = {k: v for k, v in ampl.var["Storage"].to_dict().items() if v != 0}
Storage = {k: round(v) for k, v in Storage_.items()}
# Filter non-zero demand data and adjust the index by adding n to the second element of the key (n it is additional period for pre-production stockpiling of goods in the warehouse )
Demand_data = {k: v for k, v in ampl.param["demand"].to_dict().items() if v != 0}
Demand_ = {
(key[0], key[1] + ampl.param["n"].value()): value
for key, value in Demand_data.items()
}
Demand = {k: round(v) for k, v in Demand_.items()}
# Filter non-zero values from the Produce variable and round them
Produce_ = {k: v for k, v in ampl.var["Produce"].to_dict().items() if v != 0}
Produce = {k: round(v) for k, v in Produce_.items()}
4. Visualization of the solution#
4.1. Weekly Production, Demand and Stock Summary#
from IPython.display import display, HTML
# Combine dictionaries into a DataFrame
data = {"Item": [], "Week": [], "Demand": [], "Storage": [], "Production": []}
# Populate the DataFrame
for key in Demand:
data["Item"].append(key[0])
data["Week"].append(key[1])
data["Demand"].append(Demand.get(key, 0))
data["Storage"].append(Storage.get(key, 0))
data["Production"].append(Produce.get(key, 0))
df = pd.DataFrame(data)
df = df.groupby(
["Item", "Week"], as_index=False
).sum() # Aggregate duplicates if any exist (for example, by summing)
pivot_df = df.pivot(
index="Item", columns="Week", values=["Demand", "Storage", "Production"]
) # Pivot the DataFrame to have weeks as columns
pivot_df.columns = [
f"{metric}_{week}" for metric, week in pivot_df.columns
] # Flatten the multi-level columns
# Reorder the columns
ordered_columns = []
max_weeks = pivot_df.columns.str.extract(r"_(\d+)")[0].astype(int).unique()
for week in sorted(max_weeks):
ordered_columns.extend([f"Demand_{week}", f"Production_{week}", f"Storage_{week}"])
pivot_df = pivot_df.reindex(
columns=ordered_columns
) # Reindex the DataFrame with the ordered columns
pivot_df = (
pivot_df.fillna(0).astype(int).replace(0, "")
) # Replace NaN with 0, convert to integers, and then replace 0 with empty string for display
styled_pivot_df = pivot_df.style.background_gradient(
cmap="Blues", low=0.1, high=1, axis=None
) # Apply heatmap styling with a blue colormap
# Rotate column headers
styled_pivot_df.set_table_styles(
[
{
"selector": "th.col_heading", # Selects the table header cells (column headings)
"props": [
(
"text-align",
"center",
), # Center-aligns the text within the header cells
# ('transform', 'rotate(-90deg)'),# Rotates the header text by -90 degrees
(
"font-size",
"13px",
), # Sets the font size of the header text to .. pixels
(
"max-width",
"30px",
), # Sets the maximum width of the header cells to .. pixels
# ('height', '120px'), # Sets the height of the header cells to .. pixels
(
"max-height",
"150px",
), # Sets the maximum height of the header cells to ..pixels
(
"vertical-align",
"bottom",
), # Vertically aligns the text to the bottom of the header cells
(
"word-wrap",
"break-word",
), # Enables word wrapping for long words in header cells
("white-space", "normal"),
],
}
]
) # Allows text to wrap normally within the cells
# Display the title above the DataFrame
# display(HTML("<h2 style='text-align: center;'>Weekly Production and Demand Summary</h2>"))
display(styled_pivot_df) # Display the styled DataFrame as an HTML table
| Demand_5 | Production_5 | Storage_5 | Demand_6 | Production_6 | Storage_6 | Demand_7 | Production_7 | Storage_7 | Demand_8 | Production_8 | Storage_8 | Demand_9 | Production_9 | Storage_9 | Demand_10 | Production_10 | Storage_10 | Demand_11 | Production_11 | Storage_11 | Demand_12 | Production_12 | Storage_12 | Demand_13 | Production_13 | Storage_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Item | |||||||||||||||||||||||||||
| 3HS10_1 | 3 | 10 | 7 | ||||||||||||||||||||||||
| 3HS10_2 | 2 | 8 | 1 | 7 | |||||||||||||||||||||||
| 3HS10_3 | 2 | 20 | 28 | 2 | 26 | 3 | 23 | 6 | 1 | 18 | 1 | 10 | 27 | 4 | 1 | 24 | 27 | ||||||||||
| 3HS10_4 | 2 | 4 | 15 | 2 | 13 | 2 | 11 | 1 | 4 | 14 | 9 | 8 | 13 | 1 | 2 | 14 | 6 | 15 | 22 | 8 | 1 | ||||||
| 3HS14_1 | 2 | 6 | 32 | 2 | 30 | 5 | 8 | 33 | 7 | 9 | 35 | 1 | 34 | 31 | 3 | ||||||||||||
| 3HS14_2 | 1 | 8 | 30 | 2 | 28 | 2 | 26 | 3 | 23 | 4 | 17 | 36 | 6 | 1 | 31 | 30 | 1 | 2 | |||||||||
| 3HS17_1 | 2 | 2 | 23 | 5 | 1 | 19 | 1 | 3 | 21 | 24 | |||||||||||||||||
| 3HS18_1 | 1 | 18 | 17 | 5 | 12 | 10 | 2 | ||||||||||||||||||||
| 3HS18_2 | 5 | 1 | 4 | 6 | 3 | 3 | 1 | 6 | 5 | 2 | 3 | 1 | 2 | ||||||||||||||
| 3HS18_3 | 5 | 11 | 5 | 6 | 4 | 2 | 1 | 1 | 2 | 1 | 1 | 1 | 8 | 10 | 6 | 6 | |||||||||||
| 3HS18_4 | 2 | 3 | 8 | 13 | 4 | 9 | 7 | 2 | 2 | 9 | 12 | 3 | |||||||||||||||
| 3HS31_1 | 1 | 7 | 1 | 6 | 3 | 3 | 9 | 20 | 14 | 5 | 9 | 1 | 4 | 12 | 7 | 5 | 5 | ||||||||||
| 3HS31_2 | 3 | 25 | 5 | 20 | 3 | 17 | 2 | 15 | 2 | 13 | 17 | 4 | |||||||||||||||
| 3HS31_3 | 3 | 8 | 5 | 4 | 5 | 2 | 4 | 7 | 1 | 8 | 14 | 2 | 12 | 16 | |||||||||||||
| 3HS31_4 | 3 | 4 | 1 | 3 | 4 | 2 | 1 | 8 | 9 | 3 | 6 | 2 | 4 | 8 | 1 | 8 | 15 | 2 | 4 | 17 | 14 | 3 | |||||
| 3HS31_5 | 2 | 2 | |||||||||||||||||||||||||
| 3HS31_6 | 1 | 3 | 1 | 2 | |||||||||||||||||||||||
| 3HS31_7 | 2 | 2 | |||||||||||||||||||||||||
| 3HS31_8 | 1 | 4 | 3 | 1 | 2 | ||||||||||||||||||||||
| 3HS33_1 | 3 | 2 | 2 | 4 | 1 | 3 | 4 | 16 | 15 | 2 | 13 | 7 | 6 | 2 | 1 | 5 | 11 | 8 | 2 | ||||||||
| 3HS33_2 | 1 | 5 | 7 | 6 | 1 | 5 | 1 | 4 | 8 | 6 | 1 | 3 | 2 | 4 | 5 | 14 | 9 | ||||||||||
| 3HS48_1 | 5 | 5 | 2 | 3 | 2 | 2 | 3 | 3 | 4 | 4 | 3 | 1 | 1 | ||||||||||||||
| 3HS48_2 | 4 | 2 | 3 | 4 | 1 | 4 | 8 | 5 | 5 | ||||||||||||||||||
| 3HS48_3 | 5 | 9 | 2 | 7 | 2 | 5 | 4 | 2 | 3 | 3 | |||||||||||||||||
| 3HS50_1 | 3 | 4 | 1 | 1 | 2 | 2 | 2 | 5 | 2 | 3 | 2 | 2 | 3 | 3 | |||||||||||||
| 3HS50_2 | 1 | 2 | 3 | 6 | 8 | 9 | 5 | 4 | 3 | 1 | 1 | ||||||||||||||||
| 3HS59_1 | 2 | 6 | 12 | 9 | 2 | 5 | 3 | 2 | 4 | 4 | 2 | 2 | 5 | 14 | 9 | 2 | 7 | 1 | 2 | 8 | 20 | 12 | |||||
| 3HS59_2 | 6 | 2 | 7 | 8 | 1 | 8 | 10 | 3 | 2 | 1 | 2 | 1 | 3 | 4 | 3 | 2 | 3 | 21 | 3 | ||||||||
| 3HS60_1 | 1 | 11 | 8 | 3 | 2 | 2 | 3 | 3 | 3 | 25 | 25 |
4.2. Weekly Pattern Manufacturing Quantity Plan#
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import seaborn as sns
records = [
(key[0], key[1], value) for key, value in Pattern_used.items()
] # Sample records for demonstration
df = pd.DataFrame(records, columns=["x", "y", "value"]) # Create a DataFrame
pivot_table = df.pivot(index="y", columns="x", values="value").fillna(
0
) # Pivot the DataFrame to create a matrix format
masked_table = pivot_table.mask(pivot_table == 0) # Remove zeros by masking them
plt.figure(figsize=(16, 4)) # Visualization using seaborn heatmap
heatmap = sns.heatmap(
masked_table,
annot=True,
fmt=".0f",
cmap="Blues",
# cbar_kws={'label': 'Pallets Used', 'orientation': 'vertical'},
cbar=True,
linewidths=0.01,
) # Use mask to hide NaNs
plt.gcf().axes[-1].set_position([0.75, 0.15, 0.02, 0.7]) # Adjusting color bar position
# Remove x and y axis labels if needed
plt.title("Pattern Manufacturing Quantity Plan")
plt.xlabel("Pattern ID")
plt.ylabel("Week Number")
plt.xticks(rotation=45) # Rotate x labels for better readability
plt.gca().invert_yaxis() # Invert Y-axis
plt.show()

4.3. Weekly Storage Quantity#
# Convert to DataFrame
records = [(key[0], key[1], value) for key, value in Storage.items()]
df = pd.DataFrame(records, columns=["Item", "Week", "Quantity"])
# Create a pivot table
pivot_table = df.pivot(index="Week", columns="Item", values="Quantity").fillna(0)
# Visualization using seaborn heatmap
plt.figure(figsize=(16, 4)) # Adjust the figure size as needed
sns.heatmap(
pivot_table, annot=True, fmt=".0f", cmap="Blues", cbar_kws={"label": "Quantity"}
)
plt.title("Weekly Storage Quantity per Item")
plt.xlabel("Items")
plt.ylabel("Week Number")
plt.xticks(rotation=45, ha="right") # Rotate x labels for better readability
plt.gca().invert_yaxis() # Invert Y-axis
plt.show()

4.4. Bin Usage Distribution: Item Placement by Bin#
# Function to visualize the bin packing results, showing only N bins
def visualize_bins_grid_with_y_values(Pattern_used, prodAtr_dict, N):
# Determine the unique bins from the amplvar_x keys
bins = sorted(
set(index for (_, index) in Pattern_items.keys())
) # Sort bins for consistent layout
# Specify the bins to hide
bins_to_hide = {""} # Bins to hide
bins_to_display = [
bin_index for bin_index in bins if bin_index not in bins_to_hide
] # Filter out hidden bins
# Limit to N bins
bins_to_display = bins_to_display[:N] # Adjust if you still want to limit by N
num_bins_to_display = len(bins_to_display)
# Calculate the number of rows and columns for the grid
cols = 3 # Set the number of columns for the grid
rows = math.ceil(num_bins_to_display / cols)
fig, axs = plt.subplots(rows, cols, figsize=(15, 1.8 * rows))
axs = axs.flatten() # Flatten the 2D array of axes for easy indexing
for i, bin_index in enumerate(bins_to_display):
ax = axs[i] # Select the current subplot
current_x = 0 # To place items sequentially along the X-axis
# Iterate through amplvar_x and create rectangles for items in the current bin
for (item, index), value in Pattern_items.items():
if (
value > 0 and index == bin_index
): # Only plot items assigned to the current bin
item_width = prodAtr_dict[(item, "width")]
item_height = prodAtr_dict[(item, "height")]
for _ in range(int(value)): # Create multiple rectangles if value > 1
# Create the rectangle with width and height
rect = patches.Rectangle(
(current_x, 0),
item_width,
item_height,
edgecolor="black",
facecolor="lightblue",
)
ax.add_patch(rect)
# Prepare the text to be displayed
text_content = f"{item}\n{item_width}x{item_height}"
# Determine whether to rotate based on the rectangle's dimensions
rotation_angle = 0
if (
item_width < item_height
): # Rotate if the width is smaller than the height
rotation_angle = 90
# Add the text to the rectangle with appropriate rotation
ax.text(
current_x + item_width / 2,
item_height / 2,
text_content,
ha="center",
va="center",
fontsize=10,
color="black",
rotation=rotation_angle,
rotation_mode="anchor",
)
# Move the X position forward based on item width
current_x += item_width
# Set plot limits and labels for the current bin
ax.set_xlim(0, ampl.param["binDim"]["width"]) # Adjust the width as needed
ax.set_ylim(0, ampl.param["binDim"]["height"]) # Set height limit for the bin
ax.set_aspect("auto")
# Set the title to the bin number from Pattern_items
ax.set_title(f"Bin {bin_index}") # Title for each bin plot
# Hide any unused subplots
for j in range(num_bins_to_display, len(axs)):
axs[j].axis("off") # Turn off any unused axes
plt.tight_layout() # Adjust subplots to fit into the figure area
# Create a space for the title
plt.suptitle("Item Placement by Bin", fontsize=16)
plt.subplots_adjust(
top=0.96
) # Adjusts the top of the subplots, leave space for the title
plt.show() # Show the complete figure with the specified bins
# Define bin dimensions (adjust as needed)
N = len(Pattern_items) # Set the number of bins to display
visualize_bins_grid_with_y_values(Pattern_items, prodAtr_dict, N)

5. Extensions#
Solve the problem taking into account that if the plant works then production should be exactly mode_atr[m, ‘Pallet per week’];
Combine the model of Part 2 with the model of Part 3 and solve the combined model using the Gilmore-Gomory method.
6. Appendix: Data approximation for constructing a model of the heating-cooling process of a steam chamber#
df = pd.read_csv("concrete_alpha.csv") # Load the CSV data into a pandas DataFrame
alpha_dict = {} # Initialize the dictionary for prodAtr
for index, row in df.iterrows():
index_ = int(row["Temperature"]) # Convert to int to remove .0
alpha_dict[index_] = float(row["alpha"]) # Store alpha value directly
data = { # Original data dictionary
10: 35,
20: 50,
30: 75,
40: 112.5,
50: 168.75,
60: 233.13,
70: 319.69,
80: 439.53,
90: 630.00,
}
# Create lists of temperatures and values from the dictionary
temperatures = np.array(list(data.keys()))
values = np.array(list(data.values()))
# Create an array of temperatures from 20 to 90
interp_temperatures = np.arange(
min(np.array(list(data.keys()))), max(np.array(list(data.keys()))) + 1
)
# Interpolate values for the new temperature range
interp_values = np.interp(interp_temperatures, temperatures, values)
# Create an interpolated dictionary with integer values
heatingCost = {
int(temp): int(value) for temp, value in zip(interp_temperatures, interp_values)
}